
Bloom Filters for the Perplexed
A rusty engineer's take on a potent data structure
Discussion on Hacker News.
Bloom filters are one of those simple and handy engineering tools that any engineer should have in their toolbox.
It is a space-efficient probabilistic data structure that represents a set and allows you to test if an element is in it.
They are really simple to construct and look like this:
The cool thing is that to achieve such space-efficiency Bloom filters allow for errors with an arbitrarily small probability!
Remarkably, a Bloom filter that represents a set of million items with an error rate of requires only bits ()! Irrespective of the length of each element in !
There're many kinds of Bloom filters. We'll cover the Standard Bloom Filter as it is the basis for the others and also serves as a nice intro for more advanced probabilistic set-membership data structures such as Cuckoo Filter.
What's on our menu for today?
- An introduction to standard Bloom filters
- A python based toy implementation
- Example: Efficiently Verify Compromised SSH Keys
- Applications:
- A derivation of the underlying math for the rusty-engineer :)
All code snippets can be found on Github.
Academic fellows might want to review Bloom's original paper [1]. Strikingly, Bloom has only references in his article!
Standard Bloom Filters
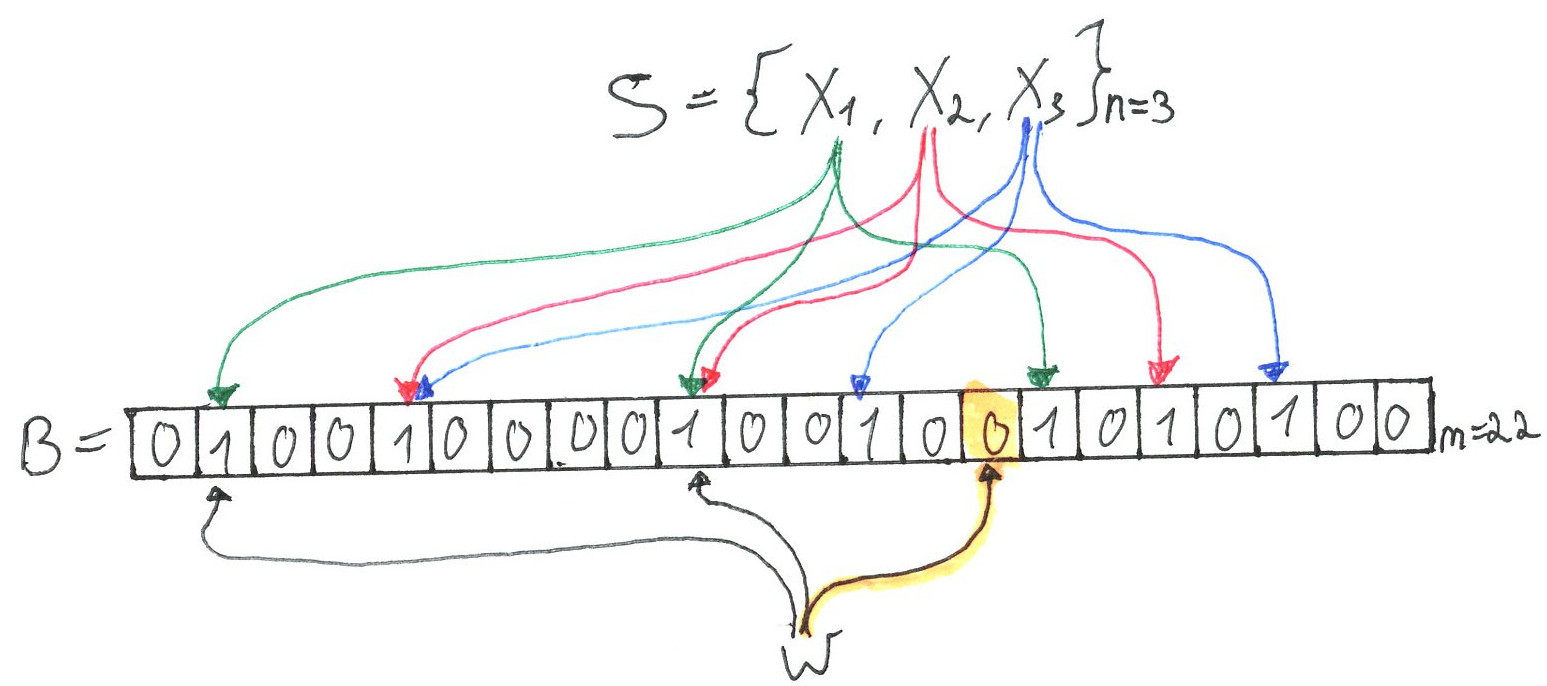
A Bloom filter represents a set of elements by an array of bits (initially set to ). Lets call it .
A Bloom filter uses independent hash functions that are assumed to be uniformly distributed over the range .
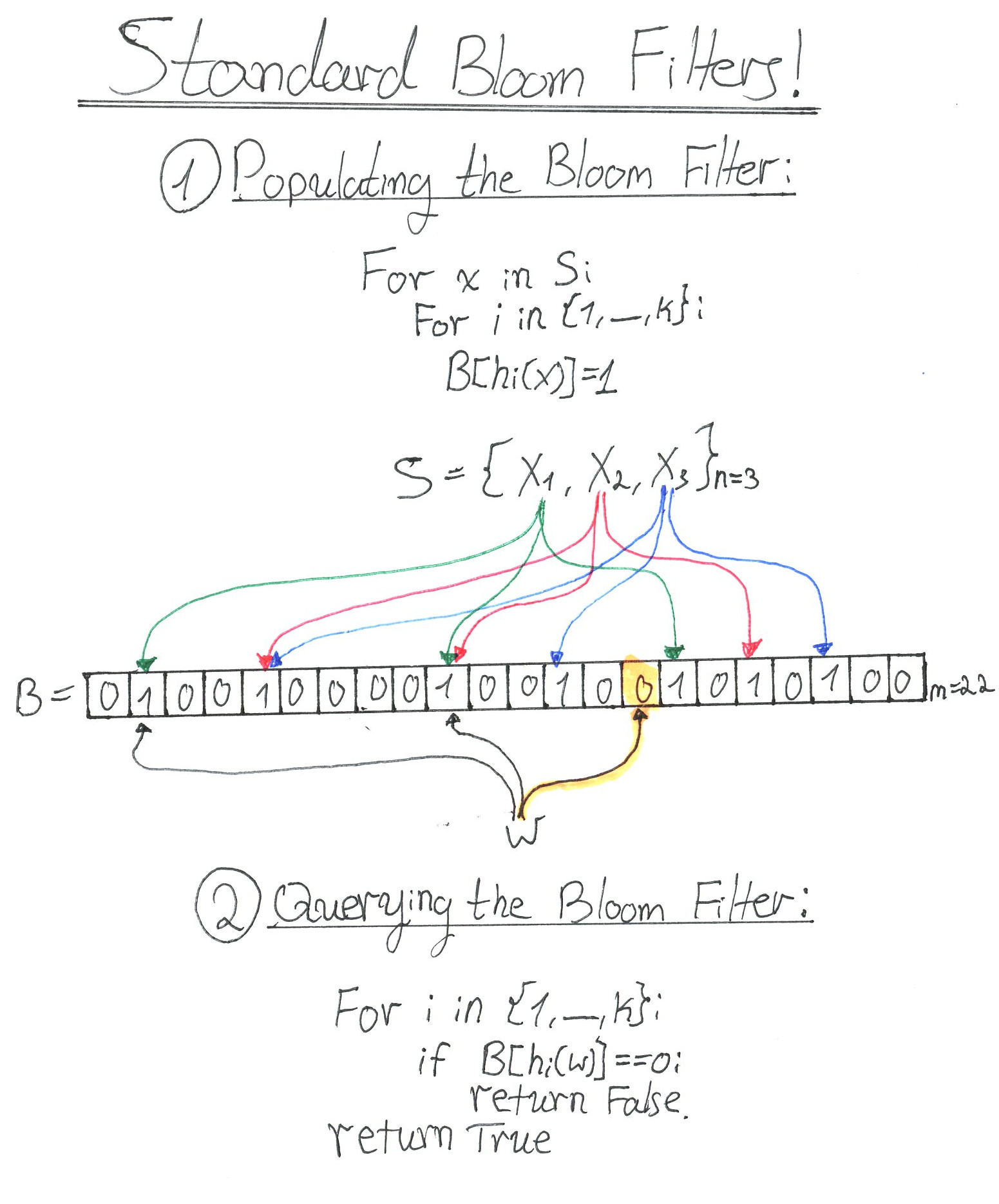
Standard Bloom filters have two operations:
1. Add() - Add to the Bloom filter.
To represent set by Bloom filter we need to Add all .
2. Contains() - Check if is in the Bloom filter.
To make things clearer, here is a hand-drawn illustration (heavily inspired by Julia Evans (@b0rk) blog illustrations):
False-Negatives and False-Positives
If Contains() returns False, clearly is not a member of . This property is why we say Bloom filters have zero false-negatives. A situation where Contains() is False and simply can't happen (because otherwise all relevant bits were ).
If Contains() returns True, may or may not be a member of . This is why we say that Bloom filters may have false-positives, because a situation where Contains() is True and can occur.
Arbitrarily Small Probability of Error (False-Positive)
The cool thing about Bloom filters is that based on (number of elements in the set ) and a chosen probability of false positives we can derive optimal (number of hash functions) and (length of bit vector ).
These are the formulae (we derive those in the Appendix):
A very cool result is that the optimal number of hash functions depends only on the false-positive probability .
Lets play with it:
import math
def optimal_km(n, p):
ln2 = math.log(2)
lnp = math.log(p)
k = -lnp/ln2
m = -n*lnp/((ln2)**2)
return int(math.ceil(k)), int(math.ceil(m))
print(optimal_km(10**6, 0.01)) # Returns (7, 9585059)
Remarkably, a Bloom filter that represents a set of million items with a false-positive probability of requires only bits () and hash functions. Only bits per element! ().
Toy Implementation
The first thing that comes to mind is how exactly do we get a family of hash functions that are uniformly distributed?
Since our objective is learning and we are not aiming for efficiency, we can simply build our family of hash functions on top of an existing hash function as a primitive. Such as SHA256.
One such construction is the following:
Where:
- - the number of the hash function.
- - the string to be hashed.
- - the length of the bit vector.
- - string concatenation.
And with Python:
def h_i(i, m, s):
return int(sha256(bytes([i]) + s).hexdigest(), 16) % m
Recall that the standard bloom filter had two simple operations:
class bloom_filter:
def __init__(self, m, k, h=h_i):
self.m = m # length of bit array
self.k = k # number of hash functions
self.h = h # hash function
self.bits = bitarray(self.m) # the actual bit store
def add(self, s):
for i in range(self.k):
self.bits[self.h(i, self.m, s)] = 1
def contains(self, s):
for i in range(self.k):
if self.bits[self.h(i, self.m, s)] == 0:
return False
return True # all bits were set
Example: Efficiently Verify Compromised SSH Keys
In 2008, Luciano Bello discovered that
Debian's OpenSSL random number generator was seriously flawed and depended
only on a process id integer.
Without getting into the gory details, essentially
it means that between 2006 and 2008, cryptographic keys that were generated
using OpenSSL on Debian-based operating systems were limited to 32768
different possible keys given their type (e.g. RSA) and size (e.g. 1024 bit).
Fortunately, g0tmi1k (@g0tmi1k), generated all possible compromised keys and uploaded them to a repo.
Say we'd like to build a system that allows users to query whether their keys were compromised.
Moreover say we'd like our system to use a minimal amount of bandwidth and/or requests to the server.
Using a bloom filter for that purpose fits perfectly! Lets see why:

Note that the initial client request is just a fetch (GET) request, the actual key X isn't sent with it.
Since Bloom filters have zero false negatives, if key isn't in Bloom filter we know that isn't compromised with certainty! Therefore, no more requests needed.
The other case is that is in :

Note that the initial client request is just a fetch (GET) request, the actual key X isn't sent with it.
So a request to verify the state of must be sent to the server as it may be either a true positive ( is in and is compromised) or a false positive ( is in but isn't compromised).
The nice thing about bloom filters is that the size of the Bloom filter is dependent on the false positive probability that is arbitrarily chosen by us!
So if we notice a lot of false positives we can just tune the Bloom filter to our needs and sacrifice some bandwidth for more accuracy.
In Github
there's test_bloom.py which populates a toy Bloom filter with
the compromised keys and tests its effectiveness:
$ ./test_bloom.py
[+] Number public keys in ./dsa/1024: 32768. Total length: 19004952 bytes (18.12Mb).
[+] False-positive probability of 0.001.
[+] Optimal number of bits is 471125 (57Kb). 322 times more space efficient.
[+] Optimal number of hash functions is 10.
[+] Test: All public keys were found within the bloom filter.
[+] Test: Average number of false positives: 21, false positive rate: 0.0213. Averaged over 10 tests, 1000 random strings in each test.
Notice that the bloom filter is more space efficient than the actual length of the public keys (18.12Mb vs. 57Kb)!
If you'd like to run it yourself make sure to follow the simple installation instructions.
For completeness, here's the code of test_bloom.py:
#!/usr/bin/env python3
`
'''A test script that queries vulnearble keys (debian openssl debacle)
in a space efficient manner using Bloom filters.'''
import glob
import random
from string import ascii_letters
import bloom
def random_string(size=10):
rand_str = ''.join(([random.choice(ascii_letters) for i in range(size)]))
return str.encode(rand_str)
def empirical_false_positive_rate(bf, nr_tests=1, nr_strings=1000):
c = 0
for i in range(nr_tests):
rand_strings = [random_string(30) for i in range(nr_strings)]
t = 0
for r in rand_strings:
if bf.contains(r):
t += 1
c += t
avg_fpr = ((c/nr_tests)*(1/nr_strings))
avg_errs = c/nr_tests
return (int(avg_errs), avg_fpr)
if __name__ == '__main__':
public_keys = set()
total_keys_bytes= 0
for pk_file in glob.glob('./dsa/1024/*.pub'):
pk_base64 = open(pk_file, 'rb').read().split()[1]
total_keys_bytes += len(pk_base64)
public_keys.add(pk_base64)
n = len(public_keys)
print('[+] Number public keys in ./dsa/1024: {}. Total length: {} bytes ({:0.2f}Mb).'.format(n, total_keys_bytes, total_keys_bytes/(2**20)))
p = 1/1000
print('[+] False-positive probability of {}.'.format(p))
k, m = bloom.optimal_km(n, p)
t = int((total_keys_bytes*8)/m)
print('[+] Optimal number of bits is {} ({}Kb). {} times more space efficient.'.format(m, int(m/(8*(2**10))), t))
print('[+] Optimal number of hash functions is {}.'.format(k))
# Populating our bloom filter.
bf = bloom.bloom_filter(m, k)
for pk in public_keys:
bf.add(pk)
# Testing that all public keys are inside the bloom filter
all_pks_in_bf = True
for pk in public_keys:
if not bf.contains(pk):
all_pks_in_bf = False
break
if all_pks_in_bf:
print('[+] Test: All public keys were found within the bloom filter.')
else:
# Can't be...
print('[-] Test: One or more public key were not found within the bloom filter.')
# Testing the empirical false positive rate by generating random strings
# (that are surely not in the bloom filter) and check if the bloom filter
# contains them.
nr_tests = 10
nr_strings = 1000
avg_errs, avg_fpr = empirical_false_positive_rate(bf, nr_tests, nr_strings)
print('[+] Test: Average number of false positives: {}, false positive rate: {:0.4f}. Averaged over {} tests, {} random strings in each test.'.format(avg_errs, avg_fpr, nr_tests, nr_strings))
Applications
In their 1994 paper, Andrei Broder and Michael Mitzenmacher coined the Bloom Filter Principle:
Wherever a list or set is used, and space is at a premium, consider using a Bloom filter if the effect of false positives can be mitigated.
Andrei Broder and Michael Mitzenmacher
Below are some cool applications I've bumped into over the years.
Breaking Bitcoin (and Ethereum) Brainwallets
In DEFCON 23 (2015), Ryan Castellucci (@ryancdotorg) presented Brainflayer. A cryptocurrency brainwallet cracker that uses a Bloom filter under the hood.
I specifically abstracted away low level Bitcoin technicalities.
Bitcoin's blockchain is made out of a sequence of blocks. Each block contains transactions and each transaction cryptographically instructs to transfer Bitcoins from a previous transaction to a Bitcoin address.
How does a Bitcoin address is generated?
A Bitcoin address is simply a hashed ECDSA public-key . Lets denote .
How does an ECDSA public key is generated?
An ECDSA public key is the outcome of multiplying a private key with some known constant base point . That is, .
How does an ECDSA private key is generated?
An ECDSA private key is simply an integer that is preferably generated using a cryptographically secure random number generator. Anyone that knows can redeem Bitcoins that were sent to .
What's a Brainwallet address?
A Brainwallet is simply a Bitcoin address where its corresponding private key was generated using a mnemonic (!) rather then a secure random number generator. One possible Brainwallet construction looks like:
For instance, the string (embedded in Bitcoin's Genesis block):
The Times 03/Jan/2009 Chancellor on brink of second bailout for banks
When hashed with SHA256 yields the following ECDSA private key:
a6d72baa3db900b03e70df880e503e9164013b4d9a470853edc115776323a098
That yields the following Bitcoin address:
1Nbm3JoDpwS4HRw9WmHaKGAzaeSKXoQ6Ej
Using a blockchain explorer we can check the address's history and see that it was used :)
Using a Bloom filter to crack Brainwallets
It is rather straight forward:
- Extract all Bitcoin addresses from the Blockchain.
- Add them to a Bloom filter .
- Generate a set of Bitcoin addresses using plausible mnemonics ("Brainwallets").
- Gather possible candidates set - addresses from that returns positive on.
- Filter out false positives by checking which addresses in exist on the Blockchain.
Currently, Bitcoin's blockchain contains about unique addresses (according to Quandl - press on Cumulative).
Ryan's implenetation contains a bloom filter of length and hash functions (he actually uses simple functions over the original public key hashes - no heavy cryptographic hash - neat).
In the Appendix we derived an experssion for the false positive probability:
Where is the number of hash functions, the length of the set and the length of the bloom filter.
def exact_pfp(n, m, k):
return ( 1 - (1 - (1/m))**(k*n) )**k
m_bytes = 512*1024*1024
m_bits = m_bytes * 8
k = 20
print(exact_pfp(440*(10**6), m_bits, k)) # ~0.063
print(exact_pfp(220*(10**6), m_bits, k)) # ~0.000137
print(exact_pfp(110*(10**6), m_bits, k)) # ~1.14e-08
print(exact_pfp(80*(10**6), m_bits, k)) # ~7.16e-11
As one can tell from above, a Bloom filter of length and hash functions has a high false positive rate on items.
In 2015, when Ryan released Brainflayer, there were about unique addresses on the blockchain and such a construction yielded a very low false postive rate of .
Today, in order to maintain a similar false positive rate, one would have to either dissect the blockchain to chunks and use several Bloom filters of length , or simply increase the length of the bloom filter and the number of hash functions.
I highly recommened you to go and watch Ryan's talk.
Recommender System Optimization
Simply put, a recommender system is an algorithm that predicts the preferences of a user.
For instance, you've just bought The Hard Thing About Hard Things. Amazon's recommender system learns that you like books about entrepreneurship and start show you other book recommendations.
But, how do you keep track of irrelevant recommendations such as books the user already read or dismissed ?
Say books were recommended by . is comprised of relevant and irrelevant recommendations ().
Using a Bloom filter to store irrelevant recommendations is one possible answer.
First, say we're dealing with a lot of irrelevant recommendations, then since Bloom filters are space efficient, it reduces the data stored per user substantially, and even bandwidth (if your logic resides in client side).
Second, since Bloom filters have zero false-negatives, we are guarunteed that a user will never be shown irrelevant recommendations (the event where and is false can't happen).
Third, since Bloom filters may have false-positives, a relevant recommendation may not be shown to the user (the event where and is true). But that's ok since nothing will happen if a user won't get a relevant recommendation once every 1K visits.
I'd like to thank Sébastien Bratières for spotting an error in this clause.
Search Engine Optimizations
In his 2016 Strange Loop talk, Dan Luu (@danluu), shared some of the internals of one of Bing's production search indices: BitFunnel (hint: they use Bloom filters, but not in a trivial way).
The talk is short and built in a very constructive way:
video: https://www.youtube.com/embed/80LKF2qph6I
You might want to review BitFunnel's SIGIR'17 paper.
Appendix
While studying the math behind Bloom filters I found myself rusty and confused. Here is a guided tour for the rusty-confused engineer :)
False-Positive Probability and Formulae
Assume Bloom filter was populated with elements from .
A false-positive is an input that isn't an element of but are all set to .
The false-positive probability then is simply the probability of having any arbitrary cells set to after Bloom filter is populated with elements from .
Lets define to be the probability that a certain bit is set to after we populate the Bloom filter.
Given , the probability of a false positive, is simply:
But, how do we calculate ?
Lets assume now that Bloom filter is empty and we begin add elements from .
Given we compute and set to . What's now?
because we assume are uniform over .
Next, we compute and set to . What's now?
Wait! Why did you subtract ?
Recall that we defined to be the probability that a specific bit is set to . This specific bit might be set to by either or or both. That is, we search for the probability of the union of independent events that are not mutually exclusive.
We subtract , since otherwise we "count" the event that both and set the bit to twice. This is due to the Inclusion-Exclusion Principle.
Doing the same thing for . What's now?
As evident from above, if we continue this way we end up with a rather intricate expression for . For this reason, most derivations of the false-positive probability use the complementary event to go around it.
Lets define to be the probability that a certain bit is not set to .
If we knew we could easily compute and :
So, how do we calculate ?
Lets start with an empty Bloom filter again and add elements from .
Given we compute and set to . What's now?
Next, we compute and set to . What's now?
Wait! Why does and differ at this stage of the analysis?
Because when calculating we wanted the probability of the event that at least one of the hash functions sets a specific bit. But, for we want the probability that all hash functions does not set a specific bit!
That is, we search for the probability of the intersection of independent events that are not mutually exclusive.
Setting the bits for the other hash functions :
And since we add elements:
Therefore:
Since we want to find the optimal and such that (the false probably rate) is minimized, we will need to differentiate it.
The expression for isn't easy to differentiate, this is why most derivations use a neat trick that represents it with (Euler's number).
One of 's many definitions is:
That is, for large enough , is approximately .
Therefore,
Hence, can be reduced to the following expression:
Although we got a nicer expression for , we would like to differentiate it with respect to (to find the the optimal number of hash functions). But is the exponent.
To differentiate such equations usually one uses some (natural logarithm) trickery.
For any function ( is simply a function of ) it holds that:
Therefore, in the case of our :
Lets denote , which makes .
Since is a monotonically increasing function minimizing is equivalent to minimizing with respect to .
Differentiating with respect to (WolframAlpha):
To find the optimal , the one that minimizes the above expression, one needs to equate it to
It is easy to verify that the derivative is when :
Great! Now we know that is the optimal number of needed hash functions.
A very cool result of bloom filters is that only depends on a given .
To achieve that result, lets plug the we got in equation we derived for the false positive probability:
Taking on both sides:
Therefore, , the number of bits in our bloom filter (number of bits in ) is:
Pluggin that into the we got yields:
And voila, depends only on a given false positive probability !
Summary
Bloom filters are simple and useful beasts. They were designed in times of great scarcity in memory, but since nowadays we explode in data they fit almost perfectly for our times as well!
If you found this article interesting, make sure to read about Scalable Bloom filters which allows you to add items to an already existing Bloom filter and Counting Bloom filters which allows you to delete items from an already existing Bloom filter.
If you spot an error / have any question please let me know so others may gain :)
Comments and thoughts are also welcome on this tweet:
Footnotes
-
B. H. Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7):422-426, 1970. ↩